Stream Processing
Stream Processing Thoughts
Kafka itself will help with reliable, fault tolerant, ordered storage of streaming messages, it's ecosystem will also help setup clusters, manage clusters, optimize streams, and enable stream processing
Stream processing engines are everywhere, with some of the most popular being Flink, Spark Streaming, Apache Storm, Delta Live Tables (sub-component built on Spark Streaming), Kafka Streams, and other open source engines and frameworks - these all have varying degrees of "real time" and "streaming", such as Apache Storm being "more real time" than Spark Streaming with more specific SLA's and less declarative frameworks
Stream processing is an extremely complex architecture to manage, and comes with many pitfalls and decisions compared to batch processing - I, in all of my time, have still never seen a use case in the world that needs full stream processing for an entire analytical stack
I personally think the decisions made between batch, stream, real time, etc are all important to consider given streaming is a "race car" you need to take care of and use in very specific circumstances, whereas batch processing (even mini-batch every minute) is more of a mini-van with reliable setups that have been proven over time in industry - don't Kafka yourself into tech debt when your SLA is daily
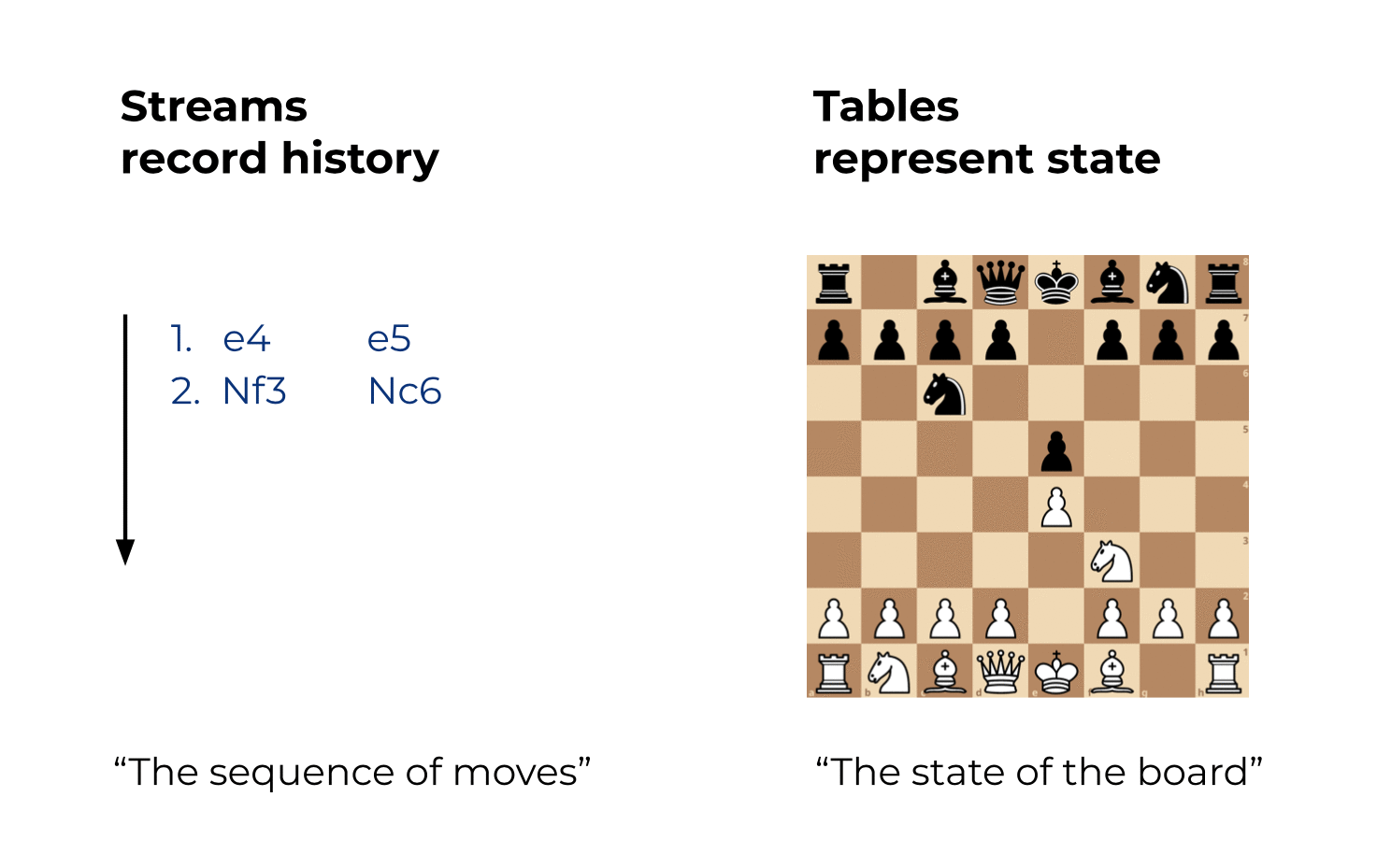
Below there's some introductions to stream processing, topics, streams, and tables along with discussing declarative ways of doing this (kSQL) versus imperative (scala stream definitions)
Stream Processing
Most of this is covering the Michael Noll Kafka Blog Now to cover stream processing - everything in stream processing is usually setup over unbounded key value streams of event data. This means it's continuously coming into the stream processing engine, and so there are new architecture components compared to typical RDBMS / batch processing
A majority of the time what needs to be covered are continuous analytical metrics such as top-k, last seen, rolling window, etc which cover past up to present, alongside stateful analytical metrics which cover present such as sum, count, max, etc. If we are looking at the top-k most listened to songs over the last 5 minutes, days, weeks, and months we will ideally want to keep a rolling count of that data coming in from the past (stream), and this will result in a stateful result set (table) we could query at any time. However, if we wanted to change it to every 10 minutes, weeks, months, etc then our table would no longer be useful and we'd have to recompute everything from our stream
- Topics are unbounded sequence of K:V pairs of raw bytes
- Kafka has topics which are partitioned and replicated, where each node in a cluster is a leader of some partitions, and a follower with replicas for others
- A topic has partitions, and each partition has a partition leader that handles read and write requests
- Order is guaranteed within partitions, so if we have a User topic and we split it up between 4 partitions, the ordering in partition 1 may "intertwine" with partition 2 and there are no guarantees between those two partitions
- A majority of times groups will try to partition and then enforce ordering inside of their consumer application logic which is an absolute anti-pattern and means you're using a tool unfit for your use case
- Scala analogy:
val topic: Seq[(Array[Byte], Array[Byte])] = Seq((Array(...)))
- Streams are the unbounded, type casted (schema enforced), K:V pair messages across partitions that we process over time. Streams are the full history of the world events from the beginning of time until today, they represent the past and present, and new events are constantly being added to the world's history
- Topics simply have
array(byte[], byte[])K:V messages, and so streams are a layer above that are supposed to define schemas and extra serialization protocols on top of them - Streams enforce schema's on read, and on write, meaning as they read in messages they will take in an avro schema and use it to decode the raw bytes into an actual typed message
- This is similar to the API Layer 7 protocols that take in raw socket bytes and create HTTP headers and messages from them! Something somewhere needs to define the format of the bytes, and in Kafka it's streams
- We can enforce contracts for these on-read and on-write layers, so that a message is never written to Kafka with a bad format, and a message that is read with a bad format is discarded / quarantined properly
- This is typically what we refer to with Avro Schema's
- Scala analogy:
val stream = topic.map { case (k: Array[Byte], v: Array[Byte]) => new String(k) -> new String(v) }- We literally just map over the corresponding schema to each portion of the message from the topic, and the result is still an unbounded stream of messages
- Topics simply have
- Tables help us with stateful processing such as joins of real time data enrichment to dimension tables, aggregations of data into some dimension table, or other operations. A table is a representation of the world today
- Even the WordCount hello world example actually results in a table, and not a stream only setup
- Since topics are partitioned, both streams and tables will also be partitioned
- Therefore, if we had something like User topic partitioned by
user_id, and we wanted a table with count of records overuser_countrywe would first need to do this aggregation per partition, and then aggregate it globally - If we did something like
count(distinct X)it's much harder because there may be repeated values across partitions you lose visibility on- For example if we wanted to count distinct countries across all users, and a user in partition 1 has US and a user in partition 2 has US, both of the counts would be included in the partition count and we'd be unable to do it globally
- Statistics that cannot be computed globally from per partition statistics are known as non-decomposable / non-commutative / non-parallelizable
- count distinct, median, percentile, etc are typically non-decomposable
- Therefore, if we had something like User topic partitioned by
- Handling these necessary requirements around metrics and backfill processing make tables a more finnicky structure
- Scala analogy:
val table = topic.map { case (k: Array[Byte], v: Array[Byte]) => new String(k) -> new String(v) }.groupBy(_._1).map { case (k, v) => (k, v.reduceLeft( (aggV, newV) => newV)._2) }- The schema is created as in streams example
.groupBy(_._1)means group by the Key in the K:V message_._2is the messagereduceLeftpart will simply perform an upsert- The
aggVis the old value, and this is unused in the upsert since we just usenewV- therefore this operation is stateless and decomposable - If we were doing a rolling count such as
aggV + 1, it would be stateful, and depending on the operation it may or may not be decomposable
- The
A topic is a queue of K:V byte pairs, streams give them typed schemas, and tables are aggregations and stateful representations of streams. In comparison to Github - streams are the commit history, and tables and the repo's at a specific commit...one is the entire history, one is the present state
| Concept | partitioned | Unbounded | Ordering | Mutable | Unique key constraint | Schema |
|---|---|---|---|---|---|---|
| Topic | Yes | Yes | Yes | No | No | No (raw bytes) |
| Stream | Yes | Yes | Yes | No | No | Yes |
| Table | Yes | Yes | No | Yes | Yes | Yes |
At this point it's important to think about what consequences this may have:
- The metrics we create over streams are "heavy" to change, and if your business requirements are constantly changing recreating these stream processing queries and backfilling is extremely expensive
- Tables help mitigate that, and also bridge stream to batch since most batch processing engines can interact with tables for downstream processing
- You want to setup your state so future changing business requirements are easy to handle and don't require new code changes and backfills
- Having access to a stream allows you to reconstruct the state of the world at any given time , but storing and recomputing everything is expensive!
Quote below from Michael Noll Confluent Blog "You certainly don’t want to build needlessly complex architectures where you must stitch together a stream(-only) processing technology with a remote datastore like Cassandra or MySQL, and probably also having to add Hadoop/HDFS to enable fault-tolerant processing (3 things are 2 too many)."
Aggregations
Streams are the only first class data structures in Kafka - A table is an aggregation of a stream, or potentially the transformations of one or more tables (which in turn are just stream aggregations)
Therefore, to understand the process end to end for a Kafka DAG of multiple streams and tables, we really just need to focus on aggregations (stream 2 stream is just mapping transforms)
- All aggregations are computed per key 1.1 All aggregations are done per partition, per key - therefore, if you use custom partitioning, your aggregation logic is much more complex
- All aggregations are continuously updated as soon as new data arrives in the input stream 2.1 Therefore, the output of an aggregation is mutable 2.2 Therefore, tables are mutable
Changelog Streams
Even though a table is an aggregation of it's input stream, it would still have an output stream! This is known as a Change Data Feed (CDF) or Changelog stream andit's counterpart in RDBMS is Change Data Capture (CDC)
Since most tables are created as upserts / incremental changes, most downstream consumers of tables can be built off of their changelog streams quite easily, this allows tables to update downstream tables (where the downstream tables are aggregations of changelog streams!)
It's actually quite easy to showcase that a simple upsert table (where value is just last one seen) would produce the exact same input stream as it's changelog stream. This brings up an interesting design choice in Kafka - most changelog streams are just piped back as topics in Kafka, and that's how it ensures reliability and durability. This relationship is known as Stream-Table Duality, and it shows how you can go from stream 2 table 2 stream 2 table.... and so on
Revisiting RDBMS vs Kafka
In RDBMS, the table is the first order construct, and so databases are really good at interacting and focusing on the "present"
In Kafka the stream is the first order construct, and tables are derivations of streams, so Kafka works primarily with the entire historic past, and because of that can also work with the present
Kafka attempts to bridge both worlds, and get the best of both worlds, by providing native support for streams and tables via Kafka Streams and kSQL which enable declarative syntax for both
Pitfalls
Kafka is great, and talking about streams above was nice, but the major pitfalls I see in Kafka are backfills, changing business logic, reliability, idempotent processing, OLAP processing, and many other items - Kafka is a racecar that can do so many great things efficiently, but it needs proper attention and care to reap the full benefits and many organizations don't have the resources or alignment to do this
Key Example: If you have an IoT job running that processes 10 messages / second, and your transformation on those messages needs to change, how do you backfill and then blue-green swap to the new transform without impacting downstream use cases? There's no "perfect solution" in these cases, and having constantly changing transformations hinders the efficiency of these architectures
Storage And Processing
Topics live in the storage layer, that's how it stores raw byte messages, how it scales out this processing, and how it ensures events are stored as we ask them to be stored
Streams, tables, and aggregations are apart of the processing layer - these tools process your events stored in raw topics by turning them into unbounded streams and tables that represent current state. Similar to how an RDBMS will take raw bytes in files and turn them into a table with indexes for us to query!
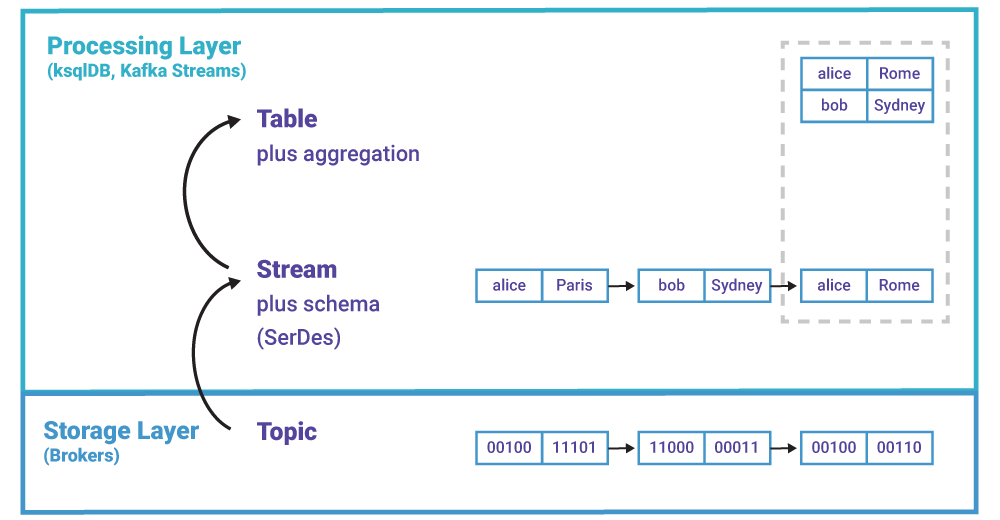
Tables are more similar to materialized views in RDBMS setting as they rely on a change being made elsewhere (new data) to be updated in the table - we don't directly update the table itself
This chart will make more sense after reading below:

Data Contracts
Data Contracts, or Schemas, are what allow producers and consumers to be able to write and read messages without talking to each other
Avro, Confluent Schema, JSON stores, etc are a way for producers and consumers to place a schema in a centralized repository, so that for a given topic consumers know how to unravel raw bytes, and producers know how to format their data into bytes
Consumers
Kafka allows you to process your data truly in parallel - we can process actual events inside of a single topic truly in parallel across multiple consumer instances. These are single application binaries launched in multiple processes that run on different containers, VM's, or physical machines
Processing data collaboratively comes with communication challenges - how do you ensure the "right" data is sent to the "right" consumer, and that these consumers don't compete / block each other? Kafka created a resource called Kafka Consumer Groups that helps to process data collaboratively
Each Consumer Group is assigned an application.id, or group.id in specific SDK's, and any new instance you want to assign to that group just takes it's ID - each group binds / subscribes itself to a number of topics, and it will use available resources in it's group to process that data
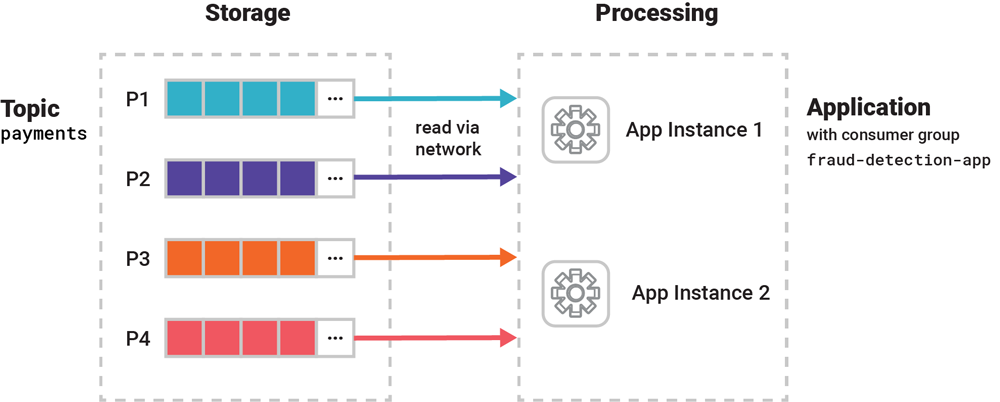
Each member instance in a group gets an exclusive slice of the data via 1+ topic partitions, the specific member instance assigned to that partition will process the data in isolation from other instances. Most K8's or container backed services can help ensure availability of Consumers via Consumer Group Protocol that helps to redistribute partitions to other members if one dies / is scaled down. When this redistribution happens the new member processing it's new partition needs to restart from some known checkpoint or offset to ensure it's not missing a chunk of data that was lost when the old member went down. This coordination process is known as rebalancing, and it's apart of the Consumer Group Protocol. Rebalancing is discussed more in the Rebalancing SubDocument
Stream Tasks
The photo above is an oversimplification - zooming into the gear icon, the actual unit of parallelism is the stream task, which can process streams, tables, and aggregations (tables)
A client application instance can be zero, one, or multiple of these tasks running, and input partitions are assigned 1:1 to stream tasks
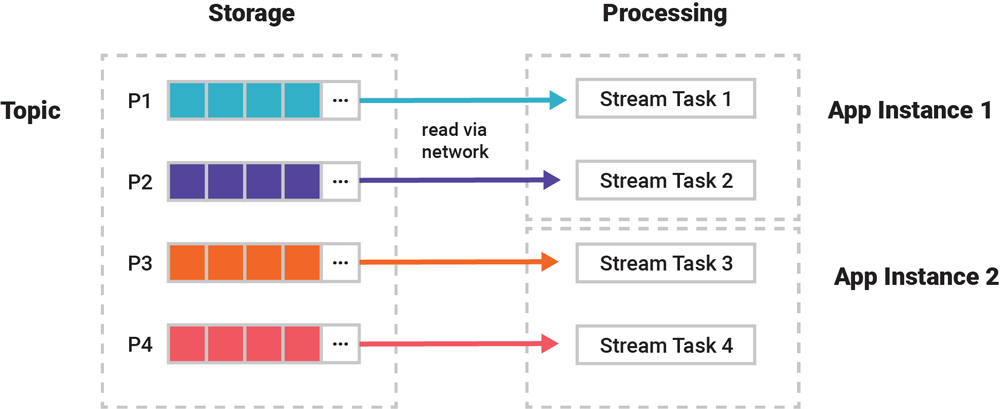
The above shows why the whole "same event key per partition" truck example setup is a strict requirement - otherwise events relating to a specific truck may be split between 2 separate stream tasks
Every task is responsible for processing one particular partition, and there are exactly as many stream tasks as there are partitions. These stream tasks are evenly assigned by Kafka to running instance of consumer application based on CPU and other factors.
Partitioned Table Processing and State Stores
Tables are stateful, meaning that they must remember something about previous events, and track variable state over distributed processing instances...this comes with many challenges
If our event.key (i.e. our partition key) is truck_id, and in an event we also have attributes like state, region, country, route_id, total_merchandise_cost for what each truck is carrying, one of the most complicated things we'd try to calculate is total_merchandise per region - if a truck crosses over regions, countries, etc we'd need to somehow ensure we uniquely process sum(total_merchandise_cost)
If we are tracking the total cost in a table fashion, we would need to track the total unique trucks per region over time, which would require us holding onto a known set of truck_id per region, per route - once a truck started a new route, we'd need to ensure the new merchandise inside of it was separated from the initial route. Tracking the set grows over time, and would be size space just to hold onto the set
After that, you also need to maintain this over a distributed system with multiple instances that can fail, events that can be duplicated (at least once, not exactly once), networking failures, etc...
These common issues were the reason NoSQL databases like Cassandra rose in populatory when traditional RDBMS weren't able to keep up with these scalability requirements...that doesn't mean RDBMS is not scalable, or that NoSQL is easier, in fact it's exactly the opposite - NoSQL databases, similar to streaming, require much more thought and orchestration compared to battle tested RDBMS
To do all of this state tracking, tables utilize state stores which are lightweight K:V databases that help us track all of the underlying state like sets of (truck_id, route_id) we discussed above
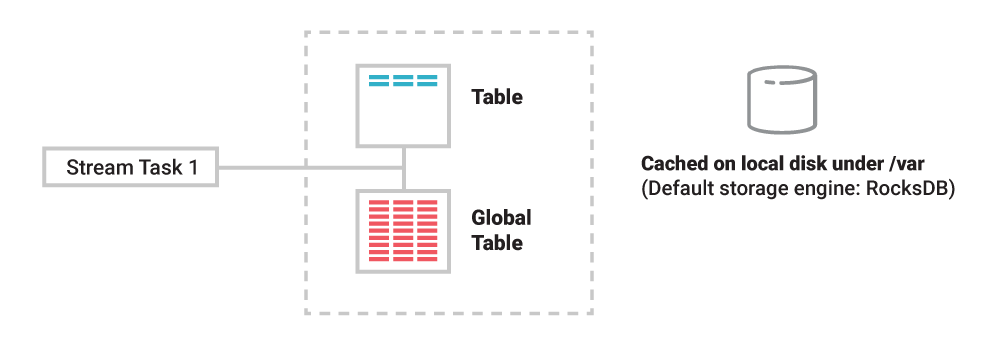
Every single table has it's own state store, and any operations carried out on the table, like querying, inserting, or updating rows, is carried out behind the scenes by a corresponding operation on the state store. These state stores are being materialized on local disk inside of the application instances (consumer processing instances) for quick access during processing. This is good because you don't need a ton of RAM to store these tables, but it is ultimately slower than RAM. Each state store is backed by RocksDB
Tables are still partitioned, and so state stores are partitioned, these are called state store instances, but state store partitions are probably smarter IMO. If a table has 10 partitions, then it's state store has 10 partitions too, and during actual processing each state store partition is maintained by one and only one stream task which will have exclusive access to the data. Below shows this - 3 streams apps, 3 partitions of a topic, 3 state stores (or the one below it with 4!)
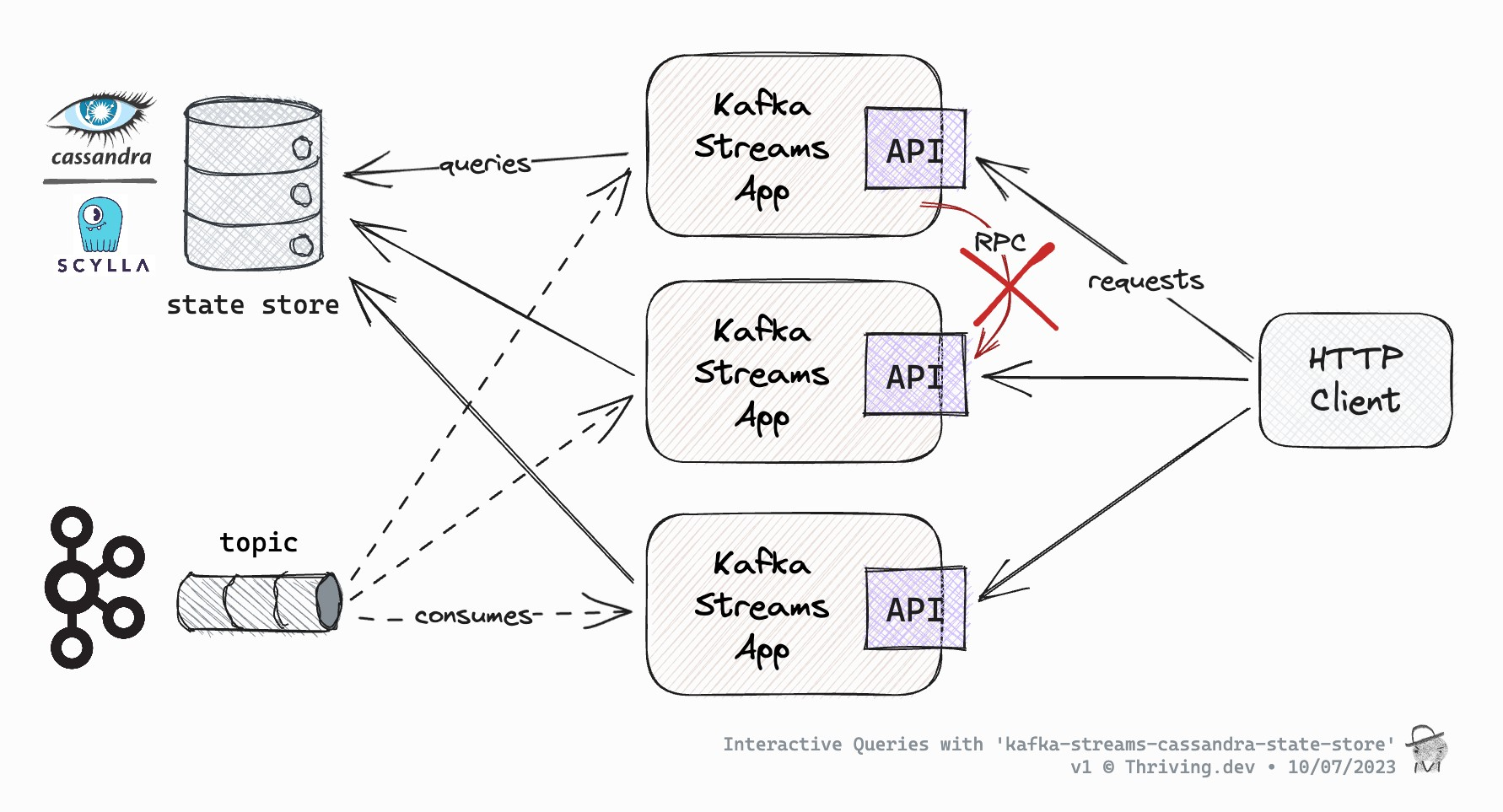
The one below is 4: Task 1 of the consumer application reads events from blue partition P1 to maintain the blue state store partition, which equates to the blue table partition
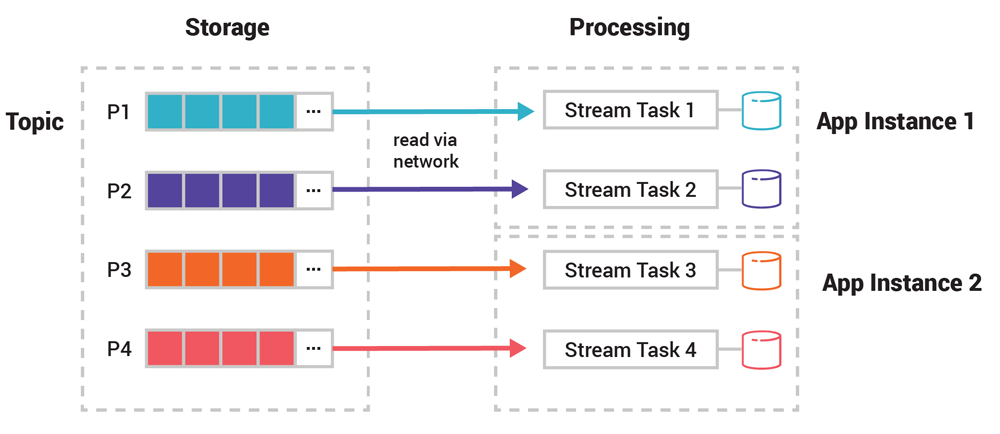
This shows the usefulness of partitions in Kafka - they allow for distributed, share nothing, stateful, and stateless processing with durable, reliable, and highly available calculations being performed on high throughput events. This is the major reason why Kafka's processing layer scales so easily
The last thing to mention is state store and table dynamics, each table has a state store, but not every state store backs a table - you can write streaming tasks with state associated to them that don't result in a table. Another use case is that you can't directly alter a table (tables are not directly mutable), but state stores allow you to directly read and write with typical PUT, GET, etc operators
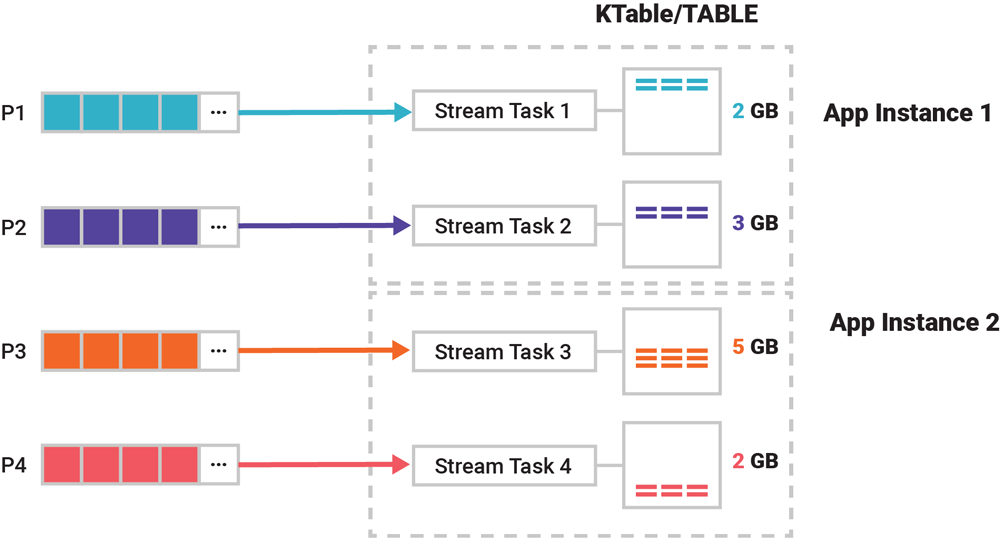
Below shows a 12GB topic split up into 4 partitions P1-P4, and how it would sit on actual consumer application servers:
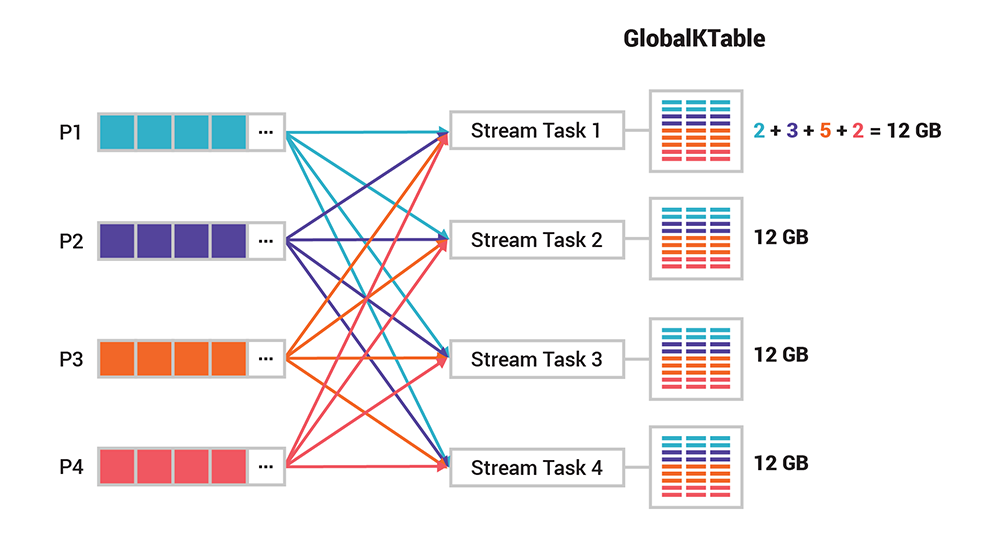
Global Tables
Sometimes there's a need to understand the world across all events - global tables are not partitioned, and they will send all events to every stream task - from the previous example there would be in total, where each stream task gets all 12GB
These are useful for things like broadcast joins where you need quick access to all data, but they come with cons around data replication and network shuffle
Storage Deep Dive
Most of the stream and table fault tolerant properties emerge simply from using disk instead of RAM - if something breaks while processing a stream, we just replay from a topic that's stored on disk on a broker node...just re-read it!
For tables, it's a bit harder because of the stateful processing and aggregations like SUM() and COUNT() - if we don't process messages exactly once, the aggregations won't be reliable
On the other hand, we can't do a ton of backtracking and checking because our system needs to be high throughput and highly performant - this is all typically remediated via state stores that are stored locally on consumer application instances, but these machines themselves can be lost or destroyed! So how do we ensure all of the consumer instance management (think ZooKeeper) is handled?
Fault Tolerance
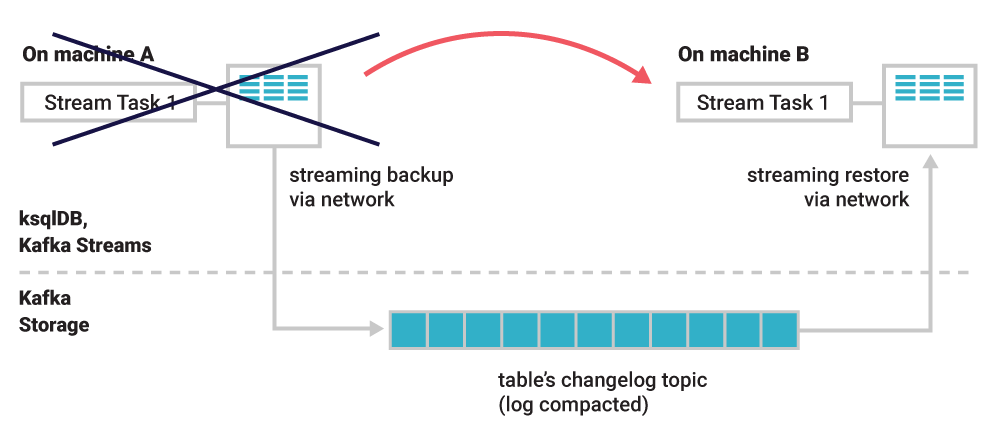
Fortunately, each table has it's own change stream, and each table is built off of data that's sitting remotely in Kafka topics. Everytime something is updated in a table, the corresponding change stream would record the actual event changing in the table - all we need to ensure is that the change stream itself is durably stored, and that other consumer applications can access it to replay events!
These change streams are stored as Kafka topics themselves - therefore, fault tolerance is achieved by exploiting the stream-table duality. Whatever happens to the stream task or container / consumer application doesn't matter, the table's data can always be correctly restored from it's change stream via the changlog topic
If a consumer application instance (container, VM, etc) dies that was calculating account balances for each event.user_id, and it needs to be rebuilt on another consumer application instance, we don't need to completely rebuild it, we can just restore the state of the table as it was when the failure happened directly from the changelog topic itself
Elasticity
Elasticity (ease of adding or removing new containers due to scaling requirments) is extremely similar to what happens in Fault Tolerance - if a cluster needs to be downsized and remove a consumer instance, it's essentially equivalent to what we wrote above
Scaling up is similar, but not exact - in this scenario we will just move stream tasks on one instance to another new instance
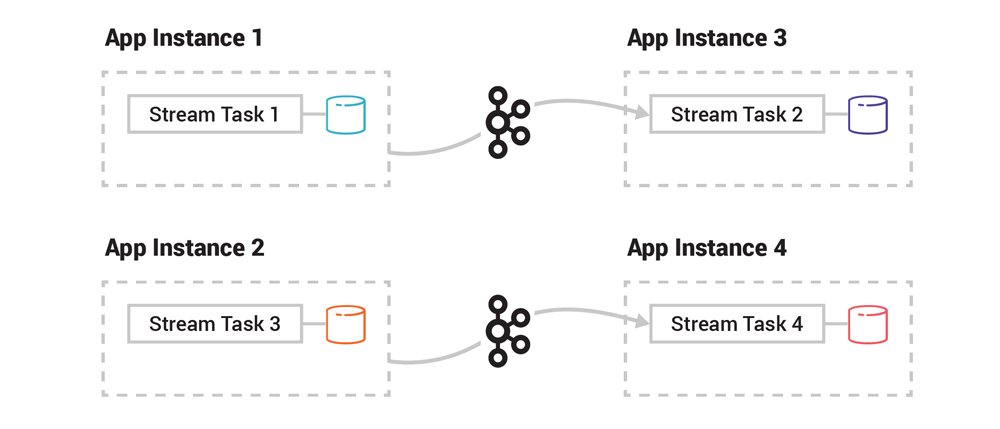
Since each application instance has the same application binary that includes all of the business processing logic, we don't have to migrate that. When a new instance is spun up we must migrate all table data, i.e. application tables state stores, to the new consumer instance via the changelog topic - the new consumer instance will just read off the changelog topic and bring itself up to speed and then at some point we need to perform a "switcheroo" and sunset the task on the old instance
Table Compaction
The discussion below is strictly for table topics! Some aggregations allow us to purge old events that aren't needed anymore
Table topics (i.e. changelog topics) are compacted - this is a feature that ensures Kafka will always retain, at a minimum, the last event for each event key within a topic partition
This helps reduce the footprint of a tables change stream in the actual Kafka broker by periodically purging old events for the same event key from storage (once it's known to be processed and unneeded)
These tables with compaction are useful because it allows you to store table data forever in Kafka as the permanent system of record without data growing out of bounds - this is great for reference data like customer profiles, product catalogues, account balances, etc
Another benefit is that recovery during rebalancing or instance failure there's much less data to be transferred over the network - if there are 1,000,000 customers with ~50 changes / day, we'd see ~50,000,000 events / day, but they are all just upserts or aggregations, then it may result in only 1,000,000 records. All that needs to be transferred is the result set, not every event.
Although it is great when your schema is fairly constant, these compaction and table semantics for reference data can fall short if you're repeatedly changing aggregation and business logic as it forces you to store all messages in topics forever for re-processing
If you do need its full history but don’t have the historic data elsewhere, such as in another stream from which the table was generated, then consider disabling compaction. And for what it’s worth, you should never enable compaction for streams because here, new events for the same key should not be interpreted as “superseding” prior events!
i.e. changing aggregation and business logic defeats the usefulness of compaction
Operational Availability
Kafka is highly available, but there are still down periods - one common one is during rebalancing, the "switcheroo" mentioned above, we'll need to take the system offline to ensure that we can rebalance appropriately and the instance switch has consistent data. This should only affect the part of the application dependent on those rebalanced partitions / tables, and the total time is just however long it takes the system to fully migrate any impacted tasks, tables, and state stores. The more data that needs to be transferred, the longer it will take - there's no way around it!
There are some ways around this by utilizing standby replicas which are application instances that are configured to maintain passive replicas of another instances table data and state. In this setup an app instance will be continuously restored to a configurable number of other instances just in case. This is helpful to reduce the total migration time during rebalancing as it significantly speeds things up, but it does cause us to replicate data in a number of different locations, increases network transmission (extra data over network), and total storage of the system would double or triple depending on number of replicas
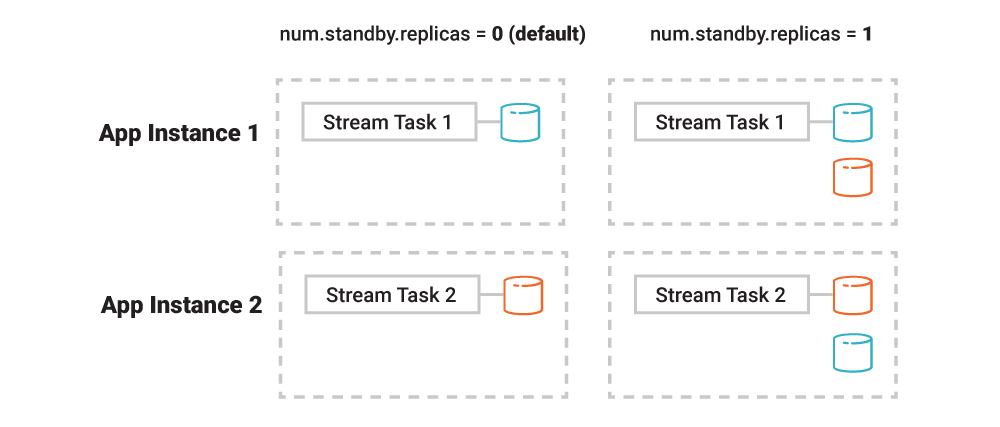
So that during a failover, we just switch instead of having to migrate data

Spark S's
Just like Spark, Kafka also deals with (some of) the 5 S's, but for the most part Kafka actually tries to force the user to avoid these 5 S's by enforcing processing on partitions only, and asking the user to avoid aggregations across partitions
The 2 worst ones in Kafka are shuffles and skew
- Shuffles would occur when aggregations are needed across different partitions, rebalancing, or generally when we need to transfer a stream tasks data to another instance
- Skew occurs naturally based on partition functions, and requires careful considerations as it will overlap business and infrastructure logic
- i.e. your processing logic is then tied to the brokers partitioning logic
Thinking above those things above, we can look into the 5 S's below
- Skew: This is a major problem on both platforms, and requires similar solutions
- Salt keys...Kafka tries to not do aggregations over separate partitioins though
- User defined partition functions
- This would help in rebalancing, but would require constant observability and reporting on if it causes issues elsewhere
- Also forces businesss logic to change because of the partitioning function
- etc...
- The best way to find this skew is via operational monitoring via datadog, confluent cloud, etc
- Shuffle: Shuffle would occur more on global tables as compared to Spark
- Spark hits these issues during joins or aggregations over non-partition keys across Stages
- Kafka by design tries to ensure the user doesn't do this
- If a join or aggregation requires keys that span multiple partitions, Kafka Streams will repartition the data. This is done by creating an internal repartition topic, where records are re-keyed and redistributed so that all records with the same join key end up in the same partition of the repartition topic
- This repartitioning (shuffling) does involve network transfer. Records are sent over the network to the appropriate partition, so that the join or aggregation can be performed locally by a single
- Serialization: This is offloaded to producers and consumers to run the actual CPU cycles
- Storage: Instead of having small file problems like Spark does, Kafka would suffer from misuses of partitions
- If your partitions are too large or too small, you'll get constant rebalancing, or require further partitioning to increase parallelism
- A Kafka application can only run as parallel as the number of partitions, so if you're seeing a clog it's most likely too few partitions
- Changing the number of partitions requires alterations to business logic, so it's not a small feat
- Spill: Kafka spills everything to disk by nature, so it's actually a feature and not a bug
OLAP, OLTP, Streaming, Batch, and Overlaps
TODO: Lambda and Kappa without storing data 85 times and losing all lineage everywhere Most companies will bridge these gaps by having stream Processing interact with OLAP data warehousing, and that brings things to [Lambda Architectures] and [Kappa Architectures]
- Stream Ingestion and Processing:
- Data is ingested into Kafka topics
- Stream processing frameworks (like Flink, Spark Streaming, Kafka Streams) process the data in real time, performing filtering, enrichment, and aggregations
- Materialized Views or Intermediate Tables:
- The results of stream processing (e.g., aggregations, stateful metrics) are written to materialized views or tables, often in a fast, mutable store (like RocksDB, Redis, or a managed state store)
- Batch Export to OLAP Store:
- Processed or raw data is periodically exported (using connectors or batch jobs) from Kafka or the stream processor to an OLAP database (like ClickHouse, Druid, BigQuery, Snowflake, Redshift, or Apache Pinot)
- This is often done via tools like Kafka Connect, custom ETL jobs, or CDC pipelines
- OLAP Querying:
- The OLAP store is used for ad-hoc analytics, dashboards, and reporting, supporting complex queries over large historical datasets
- Backfills and Reprocessing:
- For schema or business logic changes, companies often reprocess historical data from Kafka (using topic retention or archived logs) and reload the OLAP store, sometimes using batch jobs to ensure consistency